
Building Production-Grade Machine Learning Systems: A Comprehensive Guide
Machine learning (ML) has revolutionized the way businesses operate and make decisions. From personalized recommendations to predictive analytics, ML has proven to be a powerful tool for driving innovation and improving efficiency. However, building production-grade ML systems is not a trivial task. It requires a deep understanding of the entire ML lifecycle, from data preprocessing and model training to deployment and monitoring.
In this comprehensive guide, we will explore the key components and best practices for building production-grade ML systems. We will delve into the challenges and considerations at each stage of the ML lifecycle, discussing strategies and tools to overcome them. Whether you are a data scientist, ML engineer, or business leader, this guide will provide you with valuable insights and practical tips to ensure the success of your ML projects.
Understanding the ML Lifecycle: From Data to Deployment
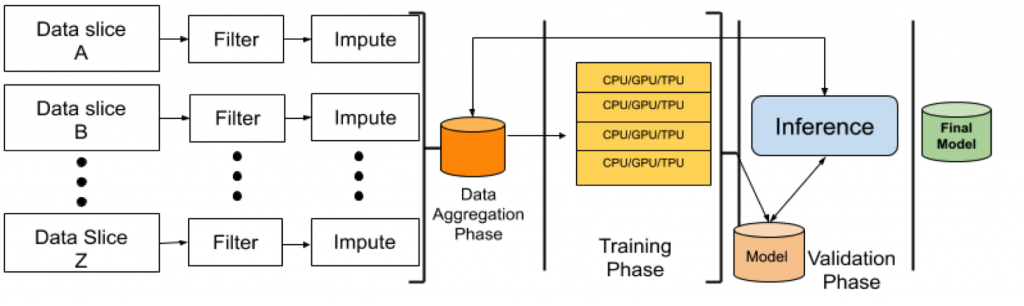
Before diving into the specifics of building production-grade ML systems, it's essential to understand the ML lifecycle. The ML lifecycle encompasses the entire process of developing and deploying ML models, from data collection and preparation to model training, evaluation, and deployment. Let's take a closer look at each stage of the ML lifecycle:
1. Data Collection and Preparation: The foundation of any ML system is data. Collecting and preparing high-quality, relevant data is crucial for building accurate and reliable models. This stage involves tasks such as data acquisition, cleaning, normalization, and feature engineering. It's important to ensure that the data is representative of the problem domain and free from biases or inconsistencies.
2. Model Training and Evaluation: Once the data is prepared, the next step is to train and evaluate ML models. This stage involves selecting appropriate algorithms, splitting the data into training and validation sets, and iteratively training and fine-tuning the models. It's crucial to evaluate the models' performance using relevant metrics and techniques, such as cross-validation and holdout validation, to ensure their generalization ability.
3. Model Deployment: After the models are trained and validated, they need to be deployed into production environments. Deployment involves integrating the models into existing systems, exposing them through APIs or user interfaces, and ensuring their scalability and reliability. It's important to consider factors such as infrastructure requirements, latency constraints, and monitoring mechanisms during the deployment process.
4. Model Monitoring and Maintenance: Deploying models is not the end of the ML lifecycle. It's essential to continuously monitor and maintain the models to ensure their performance and reliability over time. This stage involves tasks such as detecting data drift, handling concept drift, and retraining models as needed. It's important to establish feedback loops and monitoring systems to proactively identify and address any issues or degradation in model performance.
Challenges and Considerations in Building Production-Grade ML Systems
Building production-grade ML systems comes with its own set of challenges and considerations. Let's explore some of the key aspects that need to be addressed:
1. Data Quality and Governance: Ensuring the quality and integrity of data is fundamental to building reliable ML systems. It's important to establish data governance practices, including data validation, data versioning, and data lineage tracking. Implementing data quality checks, such as outlier detection and missing value handling, can help identify and mitigate data issues early in the pipeline.
2. Model Scalability and Performance: Production ML systems often need to handle large-scale data and real-time predictions. Ensuring model scalability and performance is crucial to meet the demands of production environments. This involves optimizing model architectures, leveraging distributed computing frameworks, and employing techniques like model compression and quantization to reduce model size and inference latency.
3. Model Interpretability and Explainability: As ML models become more complex and opaque, interpreting and explaining their predictions becomes increasingly important. Model interpretability and explainability are critical for building trust, ensuring fairness, and complying with regulatory requirements. Techniques such as feature importance analysis, partial dependence plots, and model-agnostic explanations can help provide insights into the model's decision-making process.
4. Model Versioning and Reproducibility: Maintaining version control and reproducibility of ML models is essential for collaboration, experimentation, and auditing purposes. It's important to establish practices for model versioning, including tracking model artifacts, hyperparameters, and training data. Tools like Git, MLflow, and DVC (Data Version Control) can help manage the versioning and reproducibility of ML pipelines.
5. Model Monitoring and Alerting: Continuously monitoring the performance and health of deployed ML models is crucial for maintaining their reliability and detecting anomalies. Implementing monitoring systems that track key metrics, such as prediction accuracy, data drift, and system resource utilization, can help proactively identify and address issues. Setting up alerting mechanisms to notify relevant stakeholders when predefined thresholds are breached is important for timely intervention.
6. Model Security and Privacy: ML systems often deal with sensitive data and make critical decisions. Ensuring the security and privacy of ML models and data is paramount. This involves implementing access controls, data encryption, and secure communication protocols. Techniques like differential privacy and federated learning can help protect user privacy while still leveraging data for model training.
7. Model Fairness and Bias: ML models can inadvertently perpetuate or amplify biases present in the training data. Ensuring model fairness and mitigating bias is crucial for building ethical and trustworthy ML systems. This involves techniques such as bias detection, fairness metrics, and algorithmic fairness techniques. It's important to regularly audit models for biases and take corrective actions to ensure equitable outcomes.
Best Practices for Building Production-Grade ML Systems
To build successful production-grade ML systems, it's important to follow best practices and adopt a systematic approach.
In UnfoldAI blog you can find a lot of details and articles how to build such systems, but let's discuss some key best practices:
1. Adopt an Iterative and Agile Development Process: Building ML systems is an iterative process that requires continuous experimentation, feedback, and refinement. Adopting an agile development methodology, such as Scrum or Kanban, can help manage the complexity and uncertainty associated with ML projects. Regular iterations, frequent feedback loops, and collaboration among cross-functional teams are essential for delivering high-quality ML systems.
2. Establish a Robust ML Pipeline: A well-designed ML pipeline is the backbone of a production-grade ML system. It encompasses the end-to-end flow of data, from ingestion and preprocessing to model training, evaluation, and deployment. Automating the ML pipeline using tools like Apache Airflow, Kubeflow, or AWS Step Functions can help ensure reproducibility, scalability, and ease of maintenance.
3. Implement Continuous Integration and Continuous Deployment (CI/CD): Applying CI/CD practices to ML systems can significantly improve the speed and reliability of model deployment. CI/CD pipelines automate the build, test, and deployment processes, ensuring that changes to the codebase and models are thoroughly validated before being pushed to production. Tools like Jenkins, GitLab CI/CD, or CircleCI can help implement CI/CD for ML systems.
4. Leverage Containerization and Orchestration: Containerization technologies, such as Docker, provide a consistent and reproducible environment for deploying ML models. Containers encapsulate the model and its dependencies, making it easier to deploy and scale across different environments. Orchestration tools like Kubernetes or Docker Swarm can help manage the deployment and scaling of containerized ML services.
5. Implement Model Serving and API Design: Deploying ML models as scalable and reliable services is crucial for production-grade systems. Model serving frameworks, such as TensorFlow Serving, MLflow, or Seldon Core, can help deploy models as REST or gRPC APIs. Designing well-defined and versioned APIs is important for integration with other systems and enabling seamless model updates.
6. Establish Monitoring and Logging Infrastructure: Implementing comprehensive monitoring and logging infrastructure is essential for observing the behavior and performance of ML systems in production. Tools like Prometheus, Grafana, and ELK stack (Elasticsearch, Logstash, Kibana) can help collect, visualize, and analyze metrics and logs. Setting up alerts and dashboards for key indicators can help proactively identify and troubleshoot issues.
7. Foster Collaboration and Knowledge Sharing: Building production-grade ML systems requires collaboration among various stakeholders, including data scientists, ML engineers, software engineers, and domain experts. Fostering a culture of knowledge sharing, documentation, and cross-functional collaboration is crucial for the success of ML projects. Regular code reviews, knowledge transfer sessions, and documentation practices can help ensure the long-term maintainability and scalability of ML systems.
8. Continuously Evaluate and Improve: Building production-grade ML systems is an ongoing process that requires continuous evaluation and improvement. Regularly assessing the performance of deployed models, gathering user feedback, and incorporating new data and insights is essential for maintaining the relevance and effectiveness of ML systems. Establishing processes for model retraining, feature engineering, and hyperparameter tuning can help keep the models up to date and aligned with changing business requirements.

Conclusion
Building production-grade ML systems is a complex and multifaceted endeavor that requires a deep understanding of the ML lifecycle, best practices, and tools. It involves addressing challenges related to data quality, model scalability, interpretability, security, and fairness. By adopting an iterative and agile development approach, establishing robust ML pipelines, implementing CI/CD practices, and leveraging containerization and orchestration, organizations can build reliable and scalable ML systems.
Collaboration, knowledge sharing, and continuous improvement are key enablers for the success of ML projects. Fostering a culture of experimentation, learning, and cross-functional collaboration can help overcome the challenges and unlock the full potential of ML in production environments.
As the field of ML continues to evolve rapidly, staying updated with the latest advancements, tools, and best practices is crucial. Engaging with the ML community, attending conferences and workshops, and learning from the experiences of others can provide valuable insights and guidance for building production-grade ML systems.
Building production-grade ML systems is not a one-time endeavor but an ongoing journey of exploration, experimentation, and refinement. By embracing this journey and adopting a systematic and best-practice-driven approach, organizations can harness the power of ML to drive innovation, improve decision-making, and create value for their customers and stakeholders.
